
- The difference between propositional and predicate logic
- How to make logic inference fast
What is the difference between propositional logic and predicate logic?
For example, "rainy", "sunny", and "windy" are propositions. Each is a complete sentence (consider, eg "it is sunny today") that describe a truth or fact, and we assume the sentence has no internal structure.In contrast, predicate logic allows internal structure of propositions in the form of predicates and functions acting on objects. For example: loves(john, mary) where "loves" is a predicate and "john", "mary" are objects. They are called first-order objects because we can use the quantifiers $\forall X, \exists X$ to quantify over them. Second-order logic can quantify over predicates and functions, and so on.
An example of a propositional machine learning algorithm is decision tree learning. This is the famous example:

All the entries are given as data, the goal is to learn to predict whether to play tennis or not, given combinations of weather conditions that are unseen before.
This would be the learned result:

The same data can also be learned by neural networks, and support vector machines. Why? Because we can encode the same data spatially like this:

where the decision boundary can be learned by a neural network or SVM. This is why I say that decision trees, ANNs, SVMs, are all spatial classifiers.
The situation is very different in the predicate logic / relational setting. For example, look at this graph where an arrow $X \rightarrow Y$ indicates "$X$ loves $Y$":
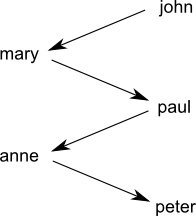
That is a sad world. This one is happier:

As a digression, sometimes I wonder if a multi-person cycle can exist in real life (eg, $John \rightarrow Mary \rightarrow Paul \rightarrow Anne \rightarrow John$), interpreting the relation as purely sexual attraction. Such an example would be interesting to know, but I guess it's unlikely to occur. </digression>
So the problem of relational learning is that data points cannot be represented in space with fixed labels. For example we cannot label people with + and -, where "+ loves -", because different persons are loved by different ones. At least, the naive way of representing individuals as points in space does not work.
My "matrix trick" may be able to map propositions to a high-dimensional vector space, but my assumption that concepts are matrices (that are also rotations in space) may be unjustified. I need to find a set of criteria for matrices to represent concepts faithfully. This direction is still hopeful.
How to make logic inference fast?
DPLL
The current fastest propositional SAT solvers are variants of DPLL (Davis, Putnam, Logemann, Loveland). Davis and Putnam's 1958-60 algorithm was a very old one (but not the earliest, which dates back to Claude Shannon's 1940 master's thesis).
Resolution + unification
Robinson then invented resolution in 1963-65, taking ideas from Davis-Putnam and elsewhere. At that time first-order predicate logic was seen as the central focus of research, but not propositional SAT. Resolution works together with unification (also formulated by Robinson, but already in Herbrand's work) which enables it to handle first-order logic.
Resolution + unification provers (such as Vampire) are currently the fastest algorithm for theorem proving in first-order logic. I find this interesting because resolution can also be applied to propositional SAT, but it is not the fastest, which goes to DPLL. It seems that unification is the obstacle that makes first-order (or higher) logic more difficult to solve.
What is SAT?
For example, you have a proposition $P = (a \vee \neg b) \wedge (\neg a \vee c \vee d) \wedge (b \vee d)$ which is in CNF (conjunctive normal form) with 4 variables and 3 clauses. A truth assignment is a map from the set of variables to {$\top, \bot$}. The satisfiability problem is to find any assignment such that $P$ evaluates to $\top$, or report failure.
Due to the extreme simplicity of the structure of SAT, it has found connections to many other areas, such as integer programming, matrix algebra, and the Ising model of spin-glasses in physics, to name just a few.
The DPLL algorithm is a top-down search that selects a variable $x$ and recursively search for satisfaction of $P$ with $x$ assigned to $\top$ and $\bot$ respectively. Such a step is called a branching decision. The recursion gradually builds up the partial assignment until it is complete. Various heuristics are employed to select variables, cache intermediate results, etc.
Edit: DPLL searches in the space of assignments (or "interpretations", or "models"). Whereas [propositional] resolution searches in the space of resolution proofs. I have explained resolution many times elsewhere, so I'll skip it here. Basically a resolution proof consists of steps of this form:
$$ \frac{P \vee Q, \quad \neg P \vee R} {Q \vee R} $$
As you can see, it is qualitatively different from DPLL's search.
How is first-order logic different?
It seems that unification is the obstacle that prevents propositional techniques from applying to first-order logic.
So what is the essence of unification? For example, if I know
"all girls like to dress pretty" and
"Jane is a girl"
I can conclude that
"Jane likes to dress pretty".
This very simple inference already contains an implicit unification step. Whenever we have a logic statement that is general, and we want to apply it to yield a more specific conclusion, unification is the step that matches the specific statement to the general one. Thus, it is unavoidable in any logic that has generalizations. Propositional logic does not allow quantifications (no $\forall$ and $\exists$), and therefore is not compressive. The compressive power of first-order logic (or above) comes from quantification and thus unification.
Transform logic inference to an algebraic problem?
I have found a nice algebraic form of logic that has the expressive power of higher-order logic and yet is even simpler than first-order logic in syntax. My hope is to transform the problem of logic inference to an algebraic problem that can be solved efficiently. So the first step is to recast logic inference as algebra. Category theory may help in this.
Unification in category theory
In category theory, unification can be construed as co-equalizer (see Rydeheard and Burstall's book Computational Category Theory). Let T be the set of terms in our logic. A substitution $\theta$ is said to unify 2 terms $(s,t)$ if $\theta s = \theta t$. If we define 2 functions $f, g$ that points from 1 to T, so that $f(1) = s$ and $g(1) = t$, then the most general unifier (mgu) is exactly the co-equalizer of $f$ and $g$ in the category T.
The book also describes how to model equational logic in categories, but the problem is that the formulas in an AGI are mainly simple propositions that are not equational. How can deduction with such propositions be recast as solving algebraic equations....?
wow, thanks for the guide
ReplyDeleteNice post .Keep sharing Artificial Intelligence Online Training
ReplyDelete